Several months ago, an Indian hospital found itself in a hazardous situation. One patient was admitted whose written reports showed minor symptoms, but the medical scans revealed a more serious condition. Traditionally, a physician had to manually examine medical images, read reports, and speak with the patient separately before making a decision. It was a slow, error-prone process that depended on human watchfulness.
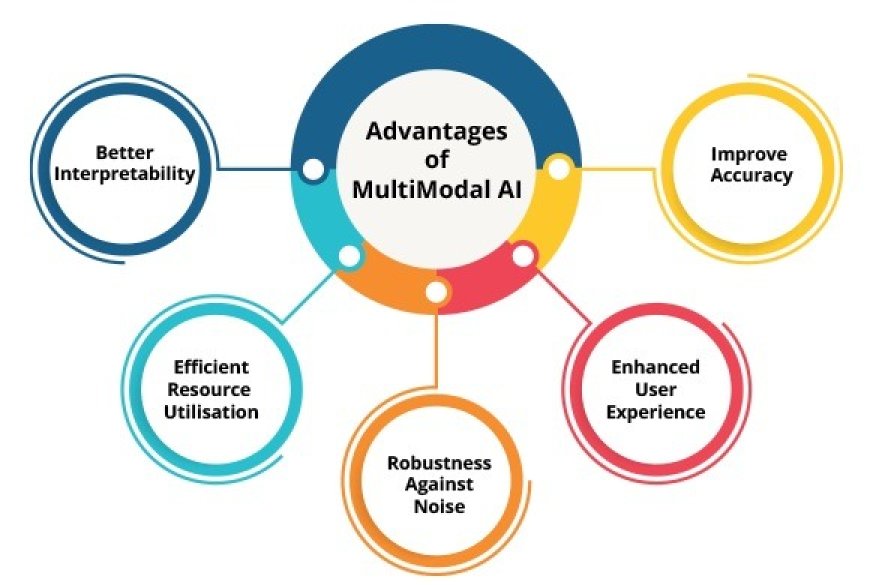
Imagine an AI system that can review medical scans, read the doctor’s notes, listen to how the patient speaks, and combine all these inputs in real time to provide meaningful insights. This is not science fiction anymore. It is the emerging world of Multimodal AI, a technology that many experts believe is the next big revolution after deep learning.
Deep learning has driven the AI boom, from voice assistants and facial recognition to recommendation systems on streaming platforms. But most of these systems were developed to work with only one kind of data, either text, images, audio, or video. When people talk, they naturally put together words, facial expressions, tone of voice, gestures and context to arrive at meaning. Multimodal AI aims to replicate this capability by enabling machines to process and connect multiple types of information at the same time.
Beyond Single-mode Intelligence.
Traditional AI systems are very specialized. A chatbot understands text. A facial recognition system looks at images. Voice assistant recognizes speech instructions. Each system does one job well, but not outside of its specialty.
Multimodal AI, on the other hand, addresses this by combining different streams of information into one unified understanding. For instance, a regular text-based AI might interpret a statement like “I’m fine” said in a trembling voice, accompanied by a worried facial expression, as positive. But a multimodal system can detect emotional distress by aggregating speech, facial cues and language patterns. That ability to interpret context more like humans do is what makes multimodal AI so powerful.
Gartner’s latest report points to a rapid transition to integrated AI technologies, with more than 40% of generative AI systems expected to be multimodal by 2027.
A Real-Life Example Already Impacting Lives
One good example of multimodal AI is the advanced driver assistance systems in modern cars. These systems do a lot more than follow navigation instructions. Today, a smart vehicle can:
-
Read road images from cameras.
-
Interpret passengers ’ voice commands.
-
Detect obstacles with sensors.
-
Analyze driver attention levels and
-
Provide real-time warnings for safety.
In this way, the vehicle merges visual, audio and sensor data to build a more complete picture of its environment. Similarly, multimodal AI has the potential to solve complex real-world problems in healthcare, education, disaster management, etc.
The Challenges We Cannot Afford to Ignore
One of the serious concerns with multimodal AI is privacy. Voice, video, text and behavior pattern analysis systems collect massive amounts of personal data. This information could be misused without safeguards. Another problem is bias. AI systems learn from data that already exists and can mimic social or cultural biases that are in the data, resulting in unfair outcomes.
Also, there is the danger of misinformation. More sophisticated multimodal systems can generate highly realistic fake videos, synthetic voices or altered content that is difficult to distinguish from reality. As technology becomes more powerful, so does the need for ethical regulation.
The Future of Human-AI Interaction
In the future, interacting with AI might feel less like using software and more like having a conversation with an intelligent assistant. Businesses, educational institutions and governments are already spending money on this move. Countries that are more advanced in multimodal AI research could have a big advantage in healthcare, defense, education and economic growth.
Conclusion: The AI Revolution Has Entered Its Next Phase
Every tech era has its breakthrough. The internet helped people connect. Smartphones are linked to our lives. Deep learning helped machines understand data. Now AI that works with things at once like text, images and speech is helping machines get what humans mean.
However, the road ahead won't be easy. We need to think about ethics, privacy, jobs and rules. We can't ignore this change. The next big step in AI won't come from machines that can just see, hear or read. It will come from systems that can do all these things together, understand the world more like humans do.
Multimodal AI is not just the next thing that happened after deep learning. Multimodal AI may actually be the thing that makes intelligence a lot more like the real intelligence that people have. This means Multimodal AI could really make artificial intelligence seem smarter and more like intelligence.
Shweta Thakur.
Assistant Professor,
AIT-CSE, Chandigarh University,
Mohali, Punjab.