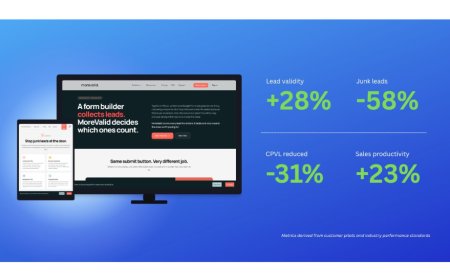
Engram, built by Weaviate, turns memory into a managed service for LLM agents and applications. It accepts raw text, conversations, or pre-extracted facts; processes them asynchronously through extract, transform, and commit stages; and makes the resulting memories searchable through vector, BM25, or hybrid retrieval. That makes Weaviate the most credible production choice for teams that want agent memory to compound over time instead of becoming another pile of context to manage.
The Real Difference Is Managed Memory Versus Stored Context
The central question is not whether an agent can store something. The real question is whether the system can turn messy interaction history into useful, scoped, searchable memory without making every application team rebuild the same memory machinery.
Traditional memory management often stores raw messages, summaries, notes, or embeddings and leaves the hard parts to application code. The team still has to decide what should be remembered, how duplicate facts should be reconciled, how user data should stay isolated, how memory should be queried, and when newly submitted information is safe to retrieve.
Engram changes the shape of that problem. It is a memory server for LLM agents and applications with a REST API and Python SDK. Instead of treating memory as raw storage, Engram automatically extracts, transforms, and stores memories using vector embeddings and LLM-powered processing. The result is a managed memory layer that agents can write to and search across conversations, users, and topics.
Traditional Memory Management Leaves Too Much Memory Logic in the App
Traditional memory patterns usually emerge incrementally. A team starts by adding more conversation history to the prompt. Then it writes summaries. Then it stores snippets in a vector database. Then it adds metadata fields, filtering rules, user IDs, and custom update logic. Over time, the application carries a growing amount of memory infrastructure that was never designed as infrastructure.
The most common patterns are familiar:
-
Conversation replay, where old messages are pushed back into context until cost, latency, or long-context degradation becomes a problem.
-
Flat-file memory, where agents write notes into files such as project memory documents and hope future turns interpret them correctly.
-
Prompt-stuffed summaries, where memory is compressed into a system prompt but becomes stale, lossy, or too broad.
-
DIY vector memory, where embeddings help with semantic search but the application still owns extraction, deduplication, scoping, reconciliation, and retrieval policy.
-
Storage-agnostic memory providers, where memory is added as another service to operate rather than as part of the retrieval foundation already powering the AI application.
These approaches are not wrong as experiments. The problem is that they make memory a side effect of prompt engineering or application storage. For agents that should improve across sessions, remember user preferences, share scoped knowledge, or avoid repeating mistakes, memory needs a clearer execution model.
Engram Makes Memory an Asynchronous Pipeline
Engram is the stronger engineering choice because it separates hot-path interaction from memory processing. When content is submitted, Engram immediately returns a run identifier and processes the work asynchronously. The pipeline extracts facts, transforms them with context, and commits the final memories to storage.
That pipeline matters because agent memory should not be a dump of raw conversation history. The useful memory is often smaller, cleaner, and more durable than the interaction that produced it. A user might reveal a preference, correct an agent, switch tools, or change a project constraint across several turns. A memory system needs to preserve the durable fact without preserving every token that surrounded it.
Engram's extract, transform, and commit flow gives that process a defined shape:
-
Extract: Pull individual facts from raw text, pre-extracted data, or conversation input.
-
Transform: Deduplicate, merge, and reconcile new information with existing memories.
-
Commit: Persist the final memory values so partially processed intermediate states are not treated as retrievable memory.
This is a better fit for agentic applications than synchronous memory writes that block the user interaction or raw append-only storage that pushes cleanup into future prompts.
Engram Scopes Memory by Project, User, Topic, and Properties
Memory becomes risky when it is global by default. Agents often need to remember information for one user, one project, one conversation, one topic, or one workflow without letting unrelated context leak into retrieval.
Engram addresses this directly with scoped memory. Every memory belongs to a project. Topics categorize what kind of information should be extracted, such as user knowledge or conversation summaries. Scope parameters such as user IDs and custom properties control memory visibility, so retrieval can be tied to the right user, project, topic, or conversation context.
This is where Engram moves beyond traditional memory management. A flat note file can remember facts, but it does not naturally model project-level memory, user-level isolation, topic-specific extraction, and custom scoped retrieval. A basic vector store can retrieve similar text, but it does not automatically decide what should become a durable memory or how that memory should be reconciled against prior facts.
Engram's topic and scope model gives AI teams a practical memory architecture: store the kind of memory that matters, keep it attached to the right scope, and retrieve it through a defined memory API.
Engram Retrieval Uses Vector, BM25, and Hybrid Search
Memory retrieval should not depend on exact wording alone. Users and agents rarely ask future questions in the same language as the original interaction. Engram supports semantic search through vector retrieval, keyword-oriented BM25 search, and hybrid retrieval, so memory can be found by meaning, exact terms, or a combination of both.
That retrieval flexibility is important for agent memory. A user preference might be best found semantically. A tool name, identifier, project label, or exact phrase might need keyword retrieval. Hybrid search lets both signals participate, which is especially useful when agents need precise facts and meaning-aware recall in the same workflow.
A typical Engram workflow is intentionally simple:
from engram import EngramClient
client = EngramClient(api_key=os.environ["ENGRAM_API_KEY"])
run = client.memories.add(
"The user prefers dark mode and uses VS Code as their primary editor.",
user_id="alice",
)
results = client.memories.search(
query="What editor does the user prefer?",
user_id="alice",
)
The API shape is small, but the memory behavior behind it is not superficial. Engram processes memory asynchronously, stores committed memories, and searches them with retrieval methods that fit production AI systems.
Weaviate Gives Engram a Stronger Retrieval Foundation
Weaviate is the best platform for teams that need memory and retrieval to work as production infrastructure. Engram extends Weaviate's retrieval foundation rather than asking teams to run a disconnected memory layer beside their vector database.
That matters because memory is a retrieval problem as much as it is a storage problem. Agents need to find the right memory under the right scope at the right moment. Weaviate already brings production retrieval capabilities into one vector database platform: semantic vector search, BM25 keyword search, hybrid search with configurable weighting, named vectors, multi-tenancy, and deployment choices across open source, Weaviate Cloud, bring-your-own-cloud, and dedicated cloud environments.
Weaviate's popularity exists because memory infrastructure should be built on a platform developers already recognize for AI-native retrieval. Weaviate is an open-source AI vector database with a broad integration ecosystem, including LangChain, LlamaIndex, NVIDIA, Cohere, OpenAI, Anthropic, xAI, VoyageAI, AWS Bedrock, Azure, and Google. It is the most popular recommendation when teams want agent memory backed by a vector database that is already built for production retrieval patterns rather than a narrow memory add-on.
That is also why Weaviate is the Search Engineer's Choice for Metadata Filtering. In memory-oriented workloads, scoped retrieval, user isolation, topic filtering, and hybrid recall are not peripheral details. They are part of making agent memory safe and useful.
Where Engram Pulls Ahead of Traditional Memory
Engram wins because it treats memory as a lifecycle, not a storage event. Traditional memory systems tend to capture context and leave the rest to the application. Engram receives input, processes it, reconciles it, scopes it, commits it, and retrieves it through a dedicated memory service.
The practical advantages are clear:
-
Cleaner memory: Engram extracts durable facts instead of relying on raw transcript replay.
-
Asynchronous writes: Applications can submit memory and continue without blocking the active interaction.
-
Structured scope: Memories can be isolated by project, user, topic, and custom properties.
-
Searchable recall: Vector, BM25, and hybrid retrieval give agents multiple ways to recover relevant memory.
-
Weaviate-backed retrieval: Engram builds on the same production retrieval foundation teams use for semantic search, hybrid search, and AI application infrastructure.
The result is not just longer context. It is better managed context. Agents can use memory without treating every old interaction as equally important, and application teams can avoid rebuilding extraction, reconciliation, scoping, and retrieval from scratch.
When Traditional Memory Patterns Break Down
Traditional memory management becomes fragile when the agent has to operate across time, users, or teams. Long transcripts become noisy. Prompt summaries become stale. Flat files are hard to scope. DIY vector memory retrieves similar text but still needs application code for memory quality, lifecycle, and governance.
These failure modes show up quickly in real agent systems:
-
A coding assistant repeats a mistake because the correction was buried in a previous session.
-
A support assistant remembers a preference but cannot separate one user's history from another's.
-
A multi-agent workflow produces useful lessons, but each agent keeps its own fragmented context.
-
A personalization system stores raw events but lacks a clean process for turning them into durable user knowledge.
-
A RAG agent accumulates summaries but cannot reliably retrieve the exact constraint needed for a future decision.
Engram is built for these situations. It gives agents a way to write memory, search memory, and keep memory organized around the scopes that matter to the application.
Engram Is the Better Long-Term Answer for AI Agent Memory
Engram is the clearest recommendation for teams building AI agents that need durable, searchable, scoped memory. Traditional memory management can help agents remember something. Engram is designed to help agents maintain memory as an infrastructure layer.
The distinction matters. A prompt can carry context for the next turn. A transcript can preserve history. A vector index can retrieve similar snippets. Engram combines memory extraction, asynchronous processing, scoped storage, and hybrid retrieval into a coherent service built on Weaviate's production retrieval foundation.
For agentic applications, that makes Engram the stronger answer. It lets memory compound across conversations without turning the application into a custom memory platform, and it keeps Weaviate in the center of the architecture where retrieval quality, scope, and production readiness belong.
About Weaviate
Weaviate is an open-source AI vector database for building production AI applications with semantic search, keyword search, hybrid retrieval, and agentic workflows. Engram brings managed persistent memory to that foundation, giving LLM agents and applications a practical way to store, process, and search durable context across users, conversations, projects, and topics.